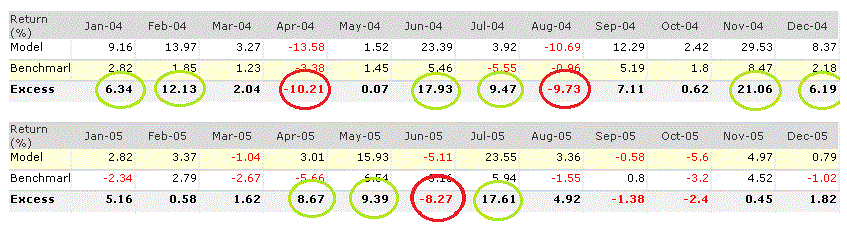
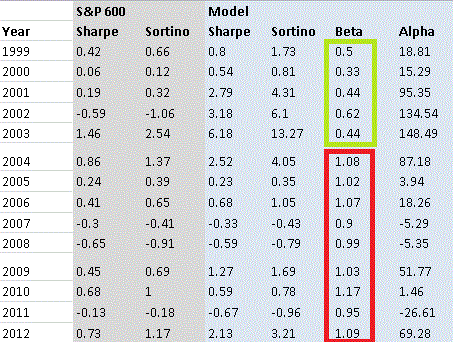
I want to explain a little more about why I think a lot of approaches to robustness are flawed.
Let’s imagine a trading system, that picks stocks based on a pseudo-random number generator.
A “pseudo” random generator is something that computers use to generate a sequence of numbers from a given starting number called a seed… They are not truely random, because it is a sequence and if you start at the same point it will produce the same set of numbers, so it is actually deterministic. However, for all intents and purposes the numbers that it spits out look random.
This is important because it means such a “backtest” is repeatable and gives the same result each time, provided the seed is a fixed constant.
This is clearly a useless trading system, we can be pretty sure of that ex-ante, because a system that selects stocks randomly is no more or no less likely to select stocks that outperform the market. It is possible to “get lucky” but then the point about trading systems is to rely on luck as little as possible - there needs to be some overall strategy.
So given how this is set up, let’s go through a thought experiment of how this might be developed. And let’s imagine that you the developer do not know that this is a pseudo-random number generator. This may be the result of latest “machine learning” or some other sophisticated formula.
After building a super computer to conduct millions of backtests, you trial a million different “trading systems”. The average performance is going to be about the same as the benchmark (less transaction costs). However, by definition, 1% of the trading systems will produce results that are in the top 1% of everything tested. Of your original million, 10,000 trading systems are in the top 1% of performance. If you analyse the trading system individually, you will conclude that it really does have some “benefit”. In fact, the probability that the results are from pure chance alone are less than 1%. All of your statistical analysis will “prove” that. Great, your really onto something.
As a contentious trader, however, you have held back an some time period for some “out of sample” testing. So we take the 10,000 top 1% and test the in our “out of sample” period. Because they are really just random, we know the average result is going to be the same as the original test - 10,000 systems with an average result likely no better than the benchmark. However, even out of those some will have done very well. If you take the top 1%, the top 100 trading systems in the out-of-sample period, their performance is likely to match the performance of the “in sample” period - in both cases, in the top 1%.
So you take these 100 trading systems, think great, they have performed in the top 1%, very unlikely by chance alone, and they have worked great in the “in sample” and “out of sample” periods. They are clearly robust and even if one or two blow up, if we diversify the money among all 100 then we should have a great result.
What happens?
Well, your result is likely to be no better than the benchmark.
Ironically, you could present such as system to your clients, and they could analyse it using the techniques mentioned and come to the conclusion that there is only a 0.01% chance the result is from luck alone. With a high degree of confidence, they will say your system really “has something” . Their analysis is correct, there is only a 0.01% chance the systems have achieved so well from luck alone. However, they really have achieved their result from luck alone. They didn’t know that what they were looking at had already been pre-selected from a million systems.
One issue is that the distinction between “out of sample” and “in sample” is something of an illusion. (It’s why I don’t like Even/Odd tests). If you use the “out of sample” period to filter out all of the trading systems that didn’t work, then really, the “out of sample” has become part of the sample.
Most people would see that it is clearly ridiculous to construct a trading system based off a pseudo-random number generator, and might think my example is rather contrived. Possibly. But if you construct a highly “sophisticated” trading system that is so advanced that even you don’t quite know what it does or why it works - how can you be sure it isn’t just a fancy pseudo-random number generator?
I think if you want “robustness” it has to involve going back to basics, establishing what is really going on, based on economic and financial principles.
I do not think the solution is “more testing”. Splitting the universe into more components, conducting more “out of sample”, more “variations” and so on may well make you “feel better”, but I hope as I have demonstrated, is useless in determining robustness.