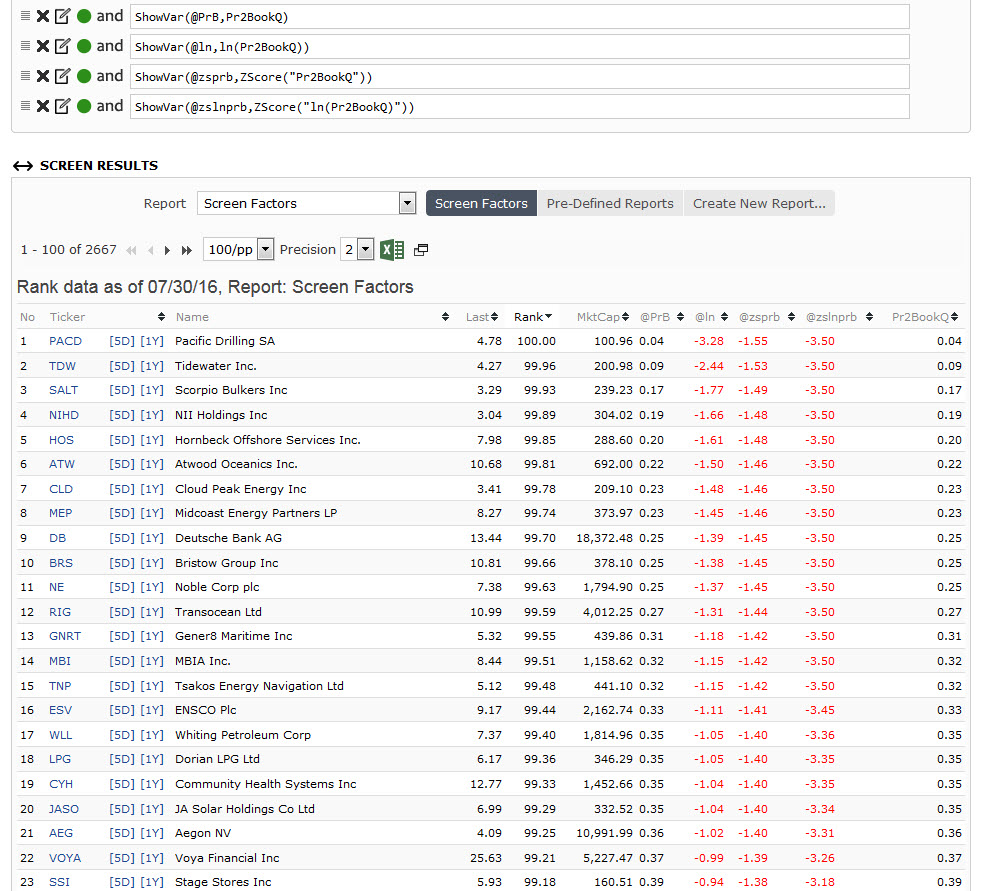
in a couple of public ranking systems I came across the use of the natural logarithmus (ln) in combination with ZScore, e.g. ZScore(“ln(Pr2BookQ)”).
Using the attached example (with simple Pr2BookQ rank, lower is better) can anybody tell me why it is better to use ln instead of the pure Pr2BookQ factor to assess the standard deviation?
There is a lot to this question. Let me take a stab at a couple easy parts.
There would be an advantage–regarding the standard deviation–if the distribution of something were lognormal. Remember Black-Shoales option pricing assumes a lognormal distribution of stock returns. If it were lognormal you would actually be getting a standard deviation of a normal distribution by taking LN first.
Of course, even stock market returns are not really lognormal as near as I can tell. Pr2BookQ distribution? Who knows.
But the other thing about this is: for a single factor none of this changes the ranking order. Not LN, not Zscore and not Zscore of LN. The rank order stays the same. So, “with simple Pr2BookQ rank, lower is better” the only difference is ZScore trims the outliers. And the trim would remain the same after taking the natural log i.e., top and bottom 7.5% for the default.
No doubt I am missing one or two of the finer points and any corrections are welcome.
I guess trimming the outliers is always a good idea. However, for the outlier trim it does not make any difference if the LN is used or not, so I still wonder what the advantage is of using LN in ZScore. If anything it only slows down computation of the ranks.