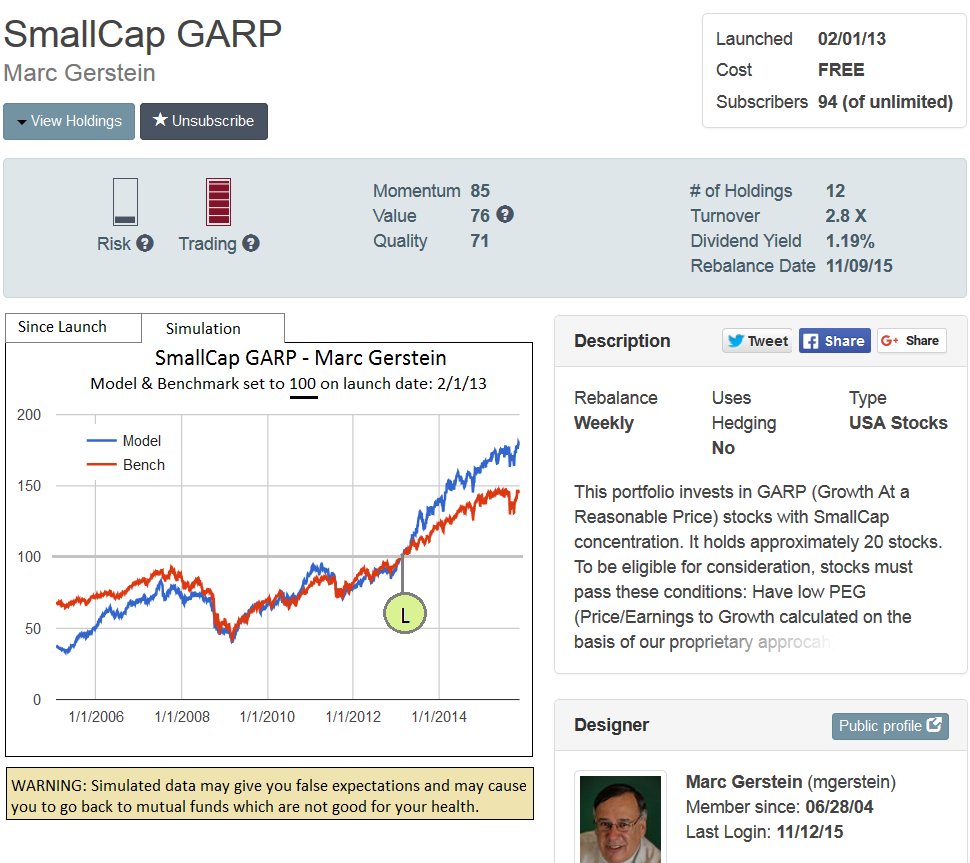
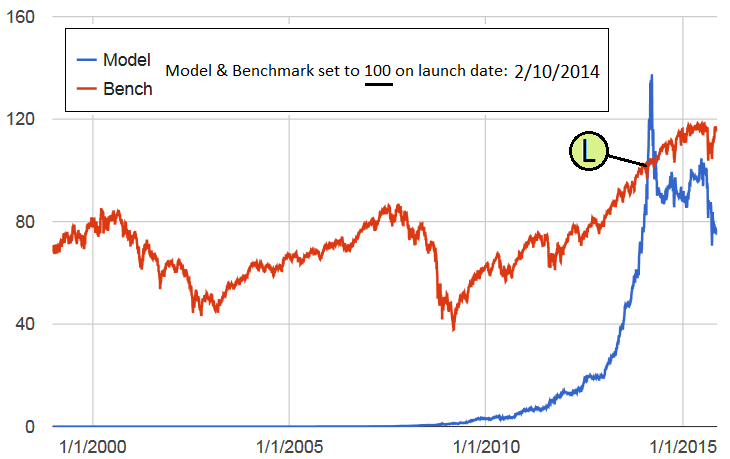
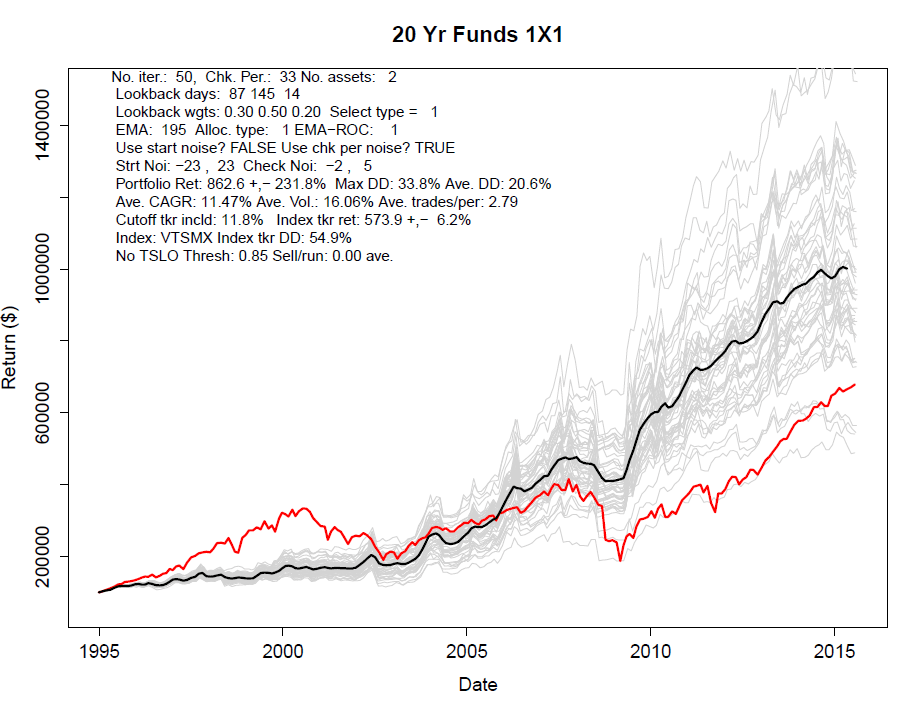
Here is an excerpt from a document originating from the Ontario Securities Commission (OSC). Although this organization is Canadian, I can assure everyone that the same policies will apply to the SEC. Canada never does this sort of thing in isolation. This guidance suggests that even model out of sample performance requires care in how it is presented and perhaps requires a client questionaire to be filled out to ascertain experience before viewing the data. It also suggests that only real performance data (i.e. trade data) should be presented to a general audience.
https://www.osc.gov.on.ca/en/SecuritiesLaw_csa_20110705_31-325_marketing-practices.htm
CSA STAFF NOTICE 31-325 – MARKETING PRACTICES OF PORTFOLIO MANAGERS
PURPOSE
Staff in various provinces from the Canadian Securities Administrators (CSA staff or we) conducted a focused compliance review (the review) of the marketing practices of firms registered as portfolio managers (PMs). This notice summarizes our findings from the review and provides guidance to portfolio managers on suggested practices in the preparation, review and use of marketing materials…
1. Preparation and use of hypothetical performance data
Hypothetical performance data is performance data that is not the performance of actual client portfolios. It is sometimes referred to as “simulated” or “theoretical” performance data and typically consists of either:
• back-tested performance data (i.e. past period), or
• model performance data (i.e. real time or future periods)
Hypothetical performance data also includes statistics such as standard deviation and Sharpe ratios, which are measures of volatility. Some of the PMs we reviewed presented the hypothetical performance data for the primary purpose of attracting new clients.
Concerns
Approximately 20% of the PMs we reviewed had deficiencies with the hypothetical performance data they presented to investors. We identified the following general concerns related to the use of hypothetical performance data:
• many investors may not have sophisticated investment knowledge sufficient to fully understand the inherent risks and limitations of this data
• any outcome may be achieved as the performance data is produced with the benefit of hindsight and is subject to potential manipulation
• the data is often combined or linked with actual client performance data, which may give the appearance of a longer track record and that the information is based entirely on actual client performance
• there is inadequate disclosure regarding the methodology and assumptions used by the PM in calculating the data
• PMs can take increased risks with the creation of hypothetical portfolios as they do not have to manage these portfolios in real market conditions
• it is difficult to verify the calculation of hypothetical performance data
Guidance
We expect PMs to market their actual client performance results. However, if a PM presents hypothetical performance data, considering the factors described above, we typically expect the following practices to be applied:
• ascertaining an investor’s level of investment knowledge sophistication, as part of the PM’s obligation to obtain KYC information and assess suitability, prior to the presentation of hypothetical performance data
• restricting the presentation to investors known to have sophisticated investment knowledge (i.e. not widely disseminating the presentation on a website or in an advertisement)
• labelling the presentation as “hypothetical” in a clear and prominent manner
• not linking the hypothetical performance data with actual performance returns of the PM. We expect hypothetical performance data to be presented separately from actual client performance data
• including clear and meaningful disclosure regarding the methodology and assumptions used to calculate the performance data, and any other relevant factors, and
• disclosing clearly a description of the inherent risks and limitations of the hypothetical performance data