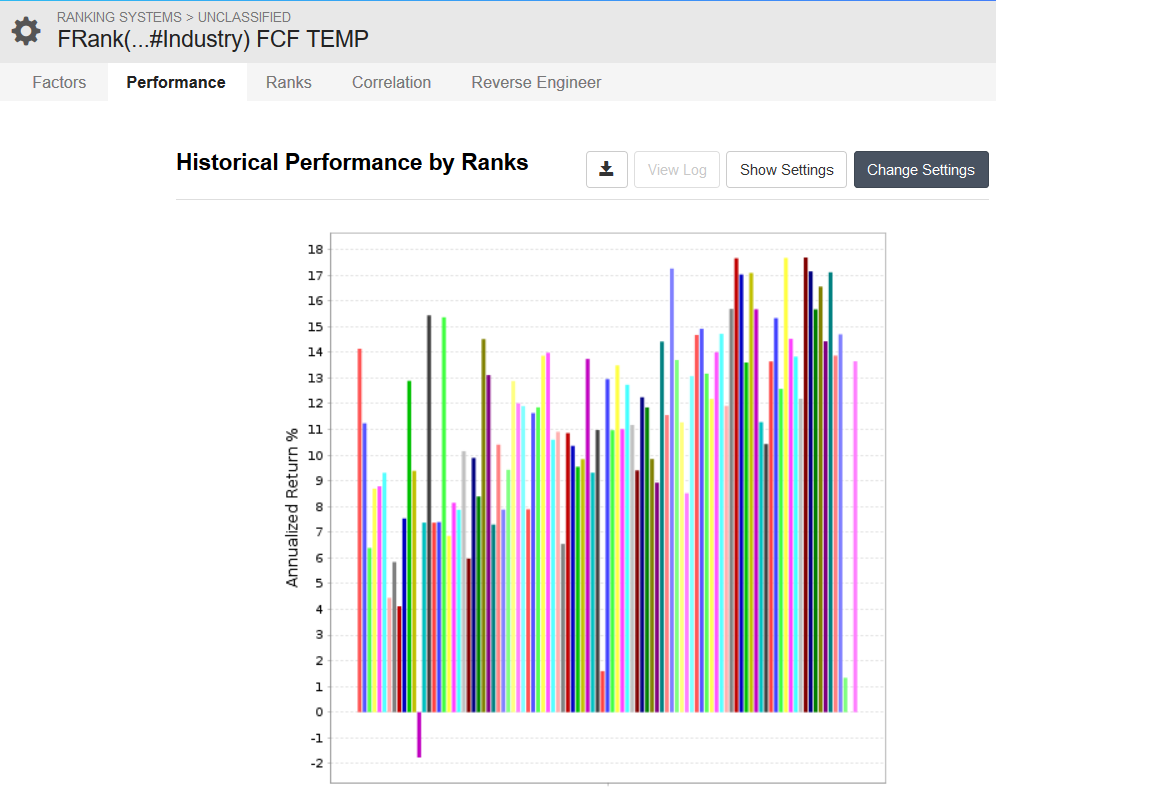
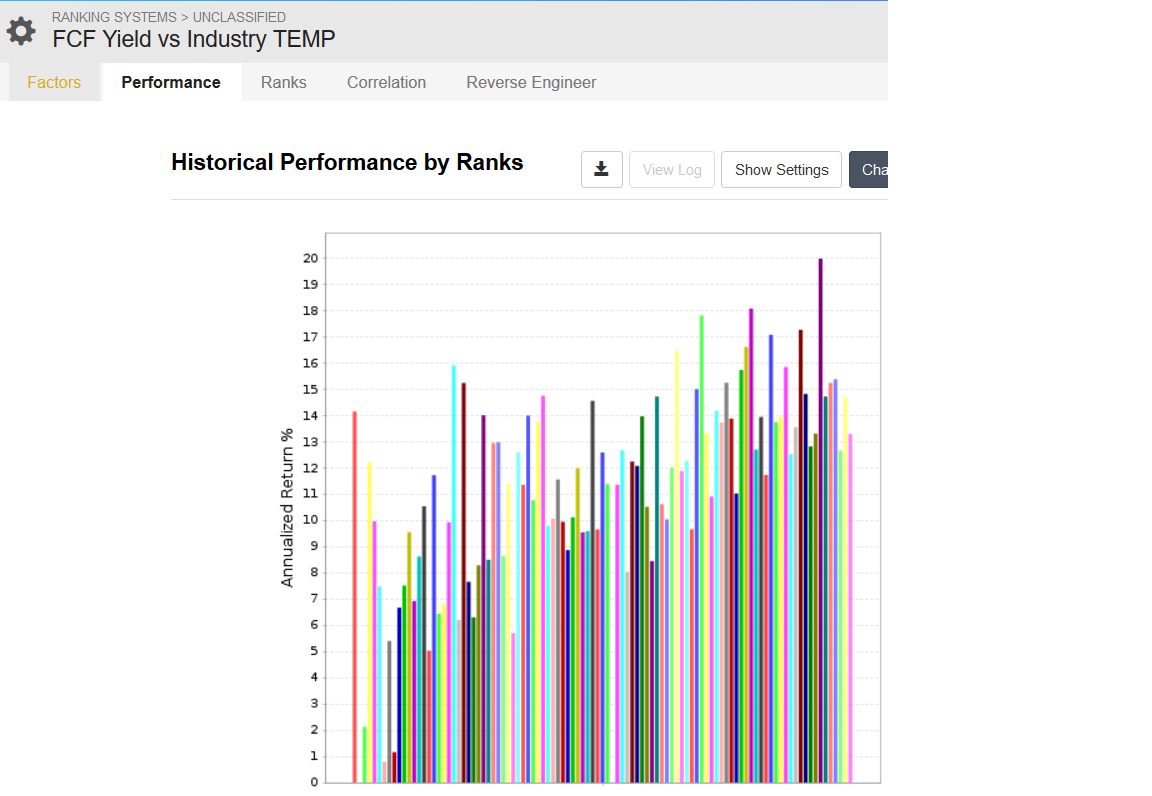
While I was searching for a way to rank vs sub industries, I came across FRank(“FCFTTM/MktCap”, #SubIndustry). So, that got me curious if FRank(“FCFTTM/MktCap”, #Industry) is the same as the [font=times new roman]Rank Formula Result vs Stocks in its Industry[/font] that’s built in to ranking systems. It turns out that there are almost the same but not quite. Below are the screen shots comparing this public ranking system that uses FRank with this one that uses the built in vs industry.
What’s the difference? Why were they made differently? Being that the built in vs industry seems to use a better algorithm, can you add vs SubSector and vs SubIndustry to the ranking system itself?
FRank and the ranking systems have one important difference in terms of the way they operate.
The top-ranked stock with FRank gets a rank of 100, and no stock gets a rank of 0. The top-ranked stock in a ranking system gets (100-100/(# of stocks)), and the bottom-ranked stock will get 0 if there are no ties or NAs.
So let’s take two industries, one with ten stocks and one with fifty. The top ranked stock in each industry using FRank will get a rank of 100, but the top ranked stocks using the ranking system will get ranks of 90 and 98. So you’re going to have a significant difference in performance depending on whether you use the ranking system or FRank. In general, ranking systems will favor stocks in more crowded industries; FRank will do the opposite and favor stocks in less crowded industries (since fewer stocks will rank close to 0).
I don’t think either one is the right or wrong way to rank. It’s up to you to decide which you want to use, and for what purpose.
Great explanation Yuval, thanks. As you know, different people have different ways of utilizing the powerful features available. Personally, I get noticeably better results using the ranking system.
Speaking as a software developer, it sounds like a relatively easy tweak. Are you able to add the SubSector and SubIndustry options in the ranking system?
I was experimenting with ranking on SubIndustry a few weeks back. An issue to overcome is that some subindustries do not have many stocks in them. Creating a fallback to use Industry if the subindustry was small seemed to help returns. I didnt get very far in my experiment, but I had this in my ranking system:
Eval(FCount(“mktcap>0”,#SubIndustry)>=20, Pr2SalesTTM / FMedian(“Pr2SalesTTM”,#SubIndustry), Pr2SalesTTM / FMedian(“Pr2SalesTTM”,#Industry))
A quick note: You’re ranking things slightly differently here.
In the system with the node FRank(“FCFTTM”,Industry) you’re not ranking the data itself, you’re ranking the rankings of the data. This means that you’re getting output that’s already gone through the ranking process once and is subject to the nitty gritty of that process.
Specifically, OTIS and VNT are in the universe and are NAs for FCFTTM. That means that they’re going to get equal positive numbers when you pipe it through FRank first at the lowest end of the rankings. If you look at the green line on the far left of the FRank chart, it’s higher in FRank than it is in the direct ranking.
That’s going to affect the buckets of everything in the system juuuuuuust a bit because now the ranking node isn’t treating OTIS and VNT as NAs anymore. I’m not 100% sure that this is material, but I think that’s what you’re observing here.
Yuval, thanks. As you know, there has been a bit of factor crowding these past few years and I am looking to tweak things to squeeze a little more juice out of factors. This is one part of that process.
I want to present the case in my feature request; why I believe that this tweak is valuable. Maybe over the weekend.
Dan, I like your train of thought. SubIndustry calls for conditional factors based on umber of stocks. I might even take this a step further and bump up certain Industries to SubSectors.
To take this concept to another level, I was thinking about doing my own reclassifying of the SubIndustries based on how their metrics compare (for example, within the same Industry you might have a few SubIndustries that are similar but one or two that are kind of different; I would want to aggregate the similar ones and not the different ones). But that’s a big project and will have to wait.
Personally, I have found that FactSet’s groupings are more sensible when it comes to this sort of thing than Compustat’s. The amount of thought and care that they put into RBICS is pretty mind-boggling when you dig deep into it. Part of it comes from the fact that most large companies operate in more than one subindustry, and they carefully delineate that and specify the amount of revenue each company makes from each subindustry it operates in. (What we offer is the subindustry from which the most revenue comes.) There’s a real science and art to this kind of classification, and RBICS is very high-quality.