Hi SteveA,
This has extreme merit, IMHO. Obviously, you have general experience in machine learning (not just neural nets). It is also painfully obvious that we do not have the tools, as you say.
If your nodes are completely uncorrelated then you eliminate the collinearity problem (or multicollinearity problem) and you could even consider using multiple regression.
This is one answer to Yuval’s original question: “alternative to optimization?”
But multiple regression has the problem of the linearity assumption. Fortunately, the whole rest of machine learning is about getting around the linearity assumption (almost).
Jim Simons (Renaissance Technologies) went far using Kernel Regression which gets around the linearity assumption. A P123 member could go far using a type of Kernel Regression (LOESS) on these uncorrelated nodes—if they had access to the data. LOESS works well, I have used it. But it is older.
BTW, if we had the tools each node could be optimized using Principle Component Analysis (PCA). So yes there are well established methods that do no involve manual optimization.
Yuval, introduced bagging to the forum. A Random Forest with bagging is non-linear. The bootstrapping also has advantages of its own for reducing overfitting. But this cannot be implemented with P123 tools—looks like Yuval tried with spreadsheets and is about to give up. Good effort!
SteveA, I am coming around to your view that one should not backtest too far so that the model changes as the market changes. ONE COULD KNOW HOW FAR BACK TO TEST IF ONE USED WALK FORWARD OPTIMIZATION as de Prado discusses extensively: basically, everywhere he writes.
If shorter backtesting methods do not work then perhaps time series analysis could help adjust the weights of ports. Perhaps something line ARIMA.
There are a bunch of smart people who have worked on the answer to Yuval’s question AND FOUND ANSWERS. One can get a graduate degree in this. One can access all of the tools through Python without having to get a graduate degree.
The people at P123 are truly intelligent people. I did not think we could reinvent the wheel so well. But we cannot keep up with Python and a bunch of people with graduate degrees here. And we cannot hope to compete with the institutions who can hire people with graduate degrees and who have experience with Python.
If we want to get beyond the wheel into the jet age, we will need Python. It is not as hard as it might seem and perhaps the forum could be used to share some script.
Honestly, if we want to see the designer models beat their benchmarks I think this will be necessary. P123 loses members when they lose money.
P123 HAS CLEARLY STOPPED BEING A QUANT SITE. P123 IS A SITE FOR PEOPLE WHO HAVE MATH PHOBIAS. I BELIEVE P123 IS MISSING OUT ON A LARGE MARKET. P123 DOES NOT ATTRACT PEOPLE WHO ALREADY KNOW THE ANSWERS TO THE QUESTIONS YUVAL KEEPS ASKING HERE ON THE FORUM. P123 DOES NOT ATTRACT PEOPLE WHO DO NOT WANT TO WAIT ON US DO GET THE ANSWERS–PEOPLE WHO KNOW THAT EVEN IF WE HAVE THE ANSWERS THE METHODS WILL NOT BE IMPLEMENTED.
P123 could attract new members if they could use basic, proven methods without having to get multiple features approved to be able to use these methods. Features—that in truth—will never be approved.
Finally, QUANTITATIVE HEDGE FUNDS OUTPERFORM HEDGE FUNDS THAT USE FUNDAMENTAL ANALYSIS. There can be no question that the methods work.
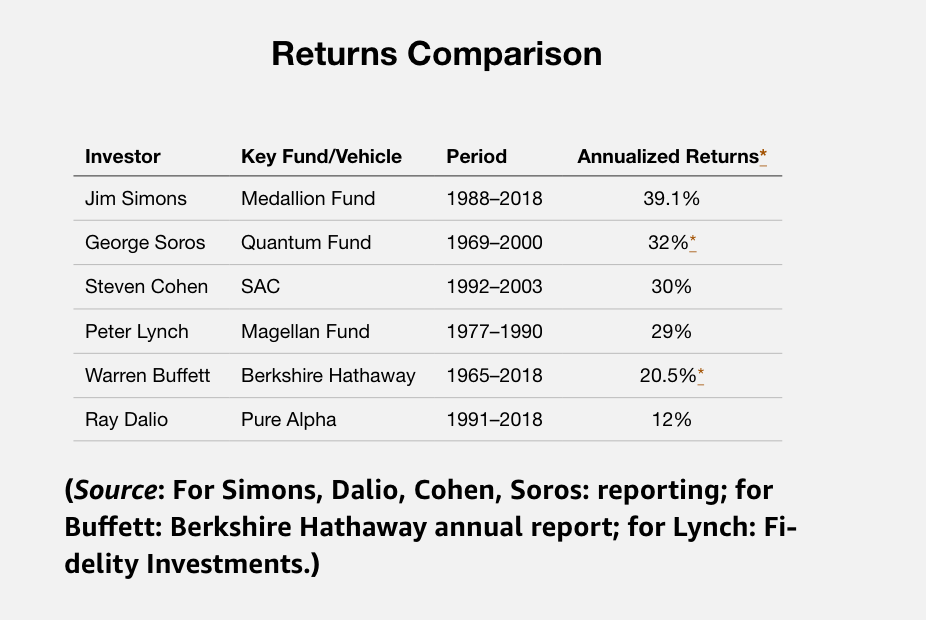
For an anecdotal example, WARREN BUFFETT IS NOT TOP DOG! Jim Simons beats him handsomely: see image.
BUFFETT’S RETURNS ARE DECLINING AS ARE THE RETURNS AT P123 I THINK. For Warren Buffett, it is a reality that he admits to frequently. Some of us are in denial.
But it is fun to reinvent the wheel. A joy to try to replicate—to the extent possible–what the institutions do using our spreadsheets.
-Jim