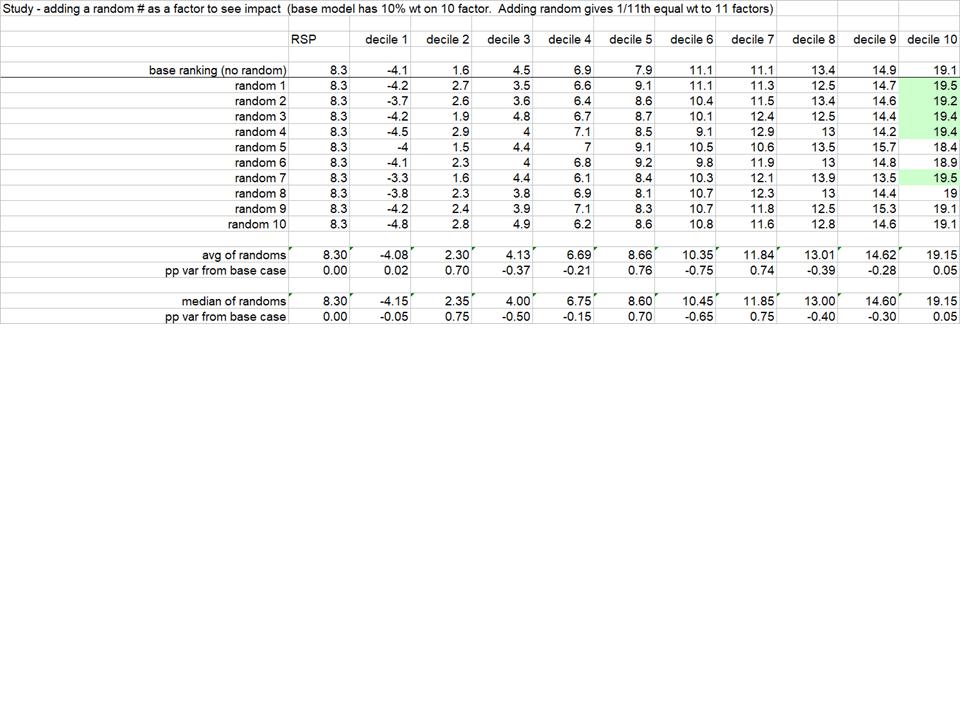
Hi all, I was playing around with adding a random number as a factor to a ranking system thinking maybe it can tell me something about the ranking system or process of building a ranking system.
What was tested: Initial model was a 10 factor ranking system with 10 equally weighted factors.
Test cases: An 11th factor represented by “Random”, a random value between 0 and 1. With this factor now the model has 11 factors with 9.09% equal wt each.
I’ll attach an image with the base model decile performance compared with the 10 runs with the “Random” factor included.
- The hypothesis going in was that adding a random factor (at 9% weight) should be expected to noticeably degrade the system.
- While the results support some slight deterioration (the performance of the bottom 50% of deciles gets slightly better and performance of the top 50% of deciles gets slightly worse), the result of 10 tests was far milder than I was expecting.
- In 5 of the 10 random cases the performance of the top decile improved, and in 2 of 10 it stayed the same. In only 3 of 10 cases did top decile performance deteriorate.
Wonderings on Ranking System construction:
- Is it surprisingly easy to confuse system improvement from including a factor, with what might be a random result?
- In many cases in the past I’ve added known individually effective factors to a model that would end up deteriorating overall model performance more than what I’m seeing here. (ex: a factor works well on it’s own, but in the context of a multifactor model it detracts from overall model performance).
- In 5 of the 10 cases adding a random factor noticeably increased top decile performance 0.1pp to 0.4pp, and makes me wonder how often I might be adding a known effective factor to a ranking system, see performance of the system improve, and conclude the factor was helpful - when it seems completely possible that factor result might just be randomly “working”. (Converse can be true also).
- Also, in a more meta sense - does the observation that adding a random factor doesn’t seem to make much difference tell me something positive or negative about the ranking system itself (robustness, likelihood of curve-fitting, etc.)?
- Am I incorrect in the expectation that adding a random factor should be expected to noticeably deteriorate results?
Anyhow, I appreciate any thoughts on this. Wasn’t what I was expecting, but not sure what to conclude from it.