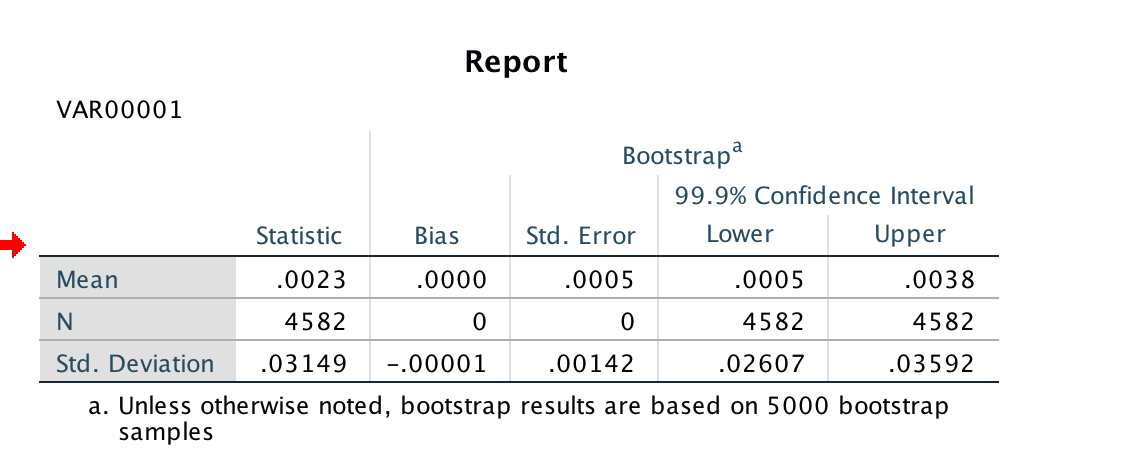
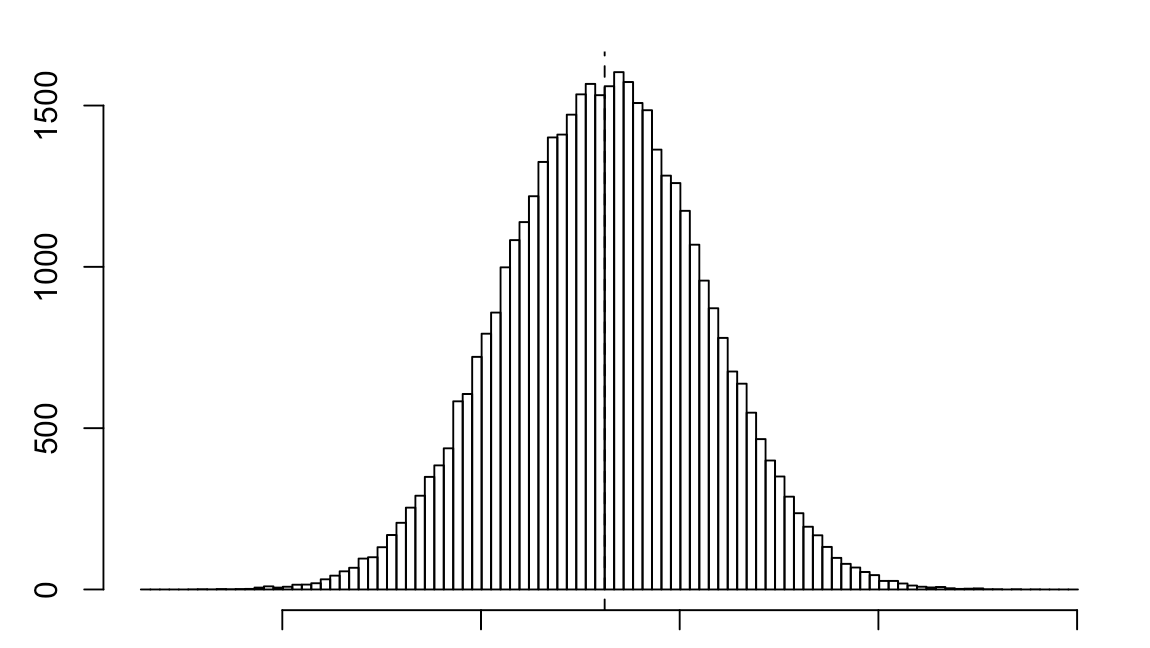
Wow!!! Thank you Guenter!!!
Just finished my first read of Aronson’s book and started with a little bit of his type of analysis: see above bootstrapping.
But his book is not about bootstrapping. Well, it is about a lot of things.
People should read this book to understand DATA-MINING BIAS. I have called it regression toward the mean. What I have called it often relates to other issues and is a very poor term. Read the book and let someone who really understands this go through it. I am a neophyte and not necessarily the most promising one at that. But people who have not read the book and just look at the pretty graphs on P123 are at a disadvantage.
If I have taken away nothing else from the book it is that: “The data miner’s mistake is using the best rule’s back-tested performance to estimate its expected performance.”
We all kind of know this. But he shows why this can never be avoided. Accepts it, and moves on to doing the best data-mining possible.
In other words, use the annualized return as part of your decision as to which sims to turn into ports but never use the annualized return as an estimate of your future return.
Now onto a few minor things:
With regard to normality. Non-parametric tests of the above example sim using SPSS continue to show a good p-value. But also using a paired t-test gives the EXACT SAME confidence interval as the bootstrapping: I looked at a 95% confidence interval for this. However you look at it, normality does not seem to be a big issue. However, bootstrapping is intended to take into account fat tails and did accomplish this in some of my anecdotal tests (I do not think SPSS is the best program for bootstrapping either). But generally speaking the central limit theorem really is a theorem and not just someone’s opinion.
On i.i.d. This is to be taken seriously. By accident and because I mimicked what Aronson had done I, at least, made my analysis stationary. This is because he uses differencing and detrending. And as I understand it using natural logs may help with this too. I will keep learning about this.
Finally, I do not think this argues against anything Marc has said. If anything it strongly makes his point that statistics can be very badly misused. We may—or may not—have a minor difference of opinion on whether properly done statistics can ever tell you anything.
But I think Marc and I would probably be in agreement that if I show you a sim in isolation, claim it is good and say “I have proved its value to the p < X level of significance and you can expect this kind of return going forward” it is …… Well, I’ll let Marc use his own expletives on that: I would not be surprised if we are using the same ones.
Aronson’s book could even be used to show why doing very few backtest and no data-mining works: as it does for Marc.
Also a careful read of the Data-Mining Bias would make one want to use rational rules that have the highest chance of being effective (best Bayesian priors).
These are the rules that Marc is recommending based on a great deal of experience and education. I use them: see above about being a neophyte and not the most promising one at that, however.
Thank you Marc, David (Primus) and Guenter. Discussing this is a big part of my beginning to understand it. BTW, you can do R on Macs (thanks).
-Jim