We had this discussion before.
Historic data should not be revised, because simulations run today do not match portfolios with the same rules.
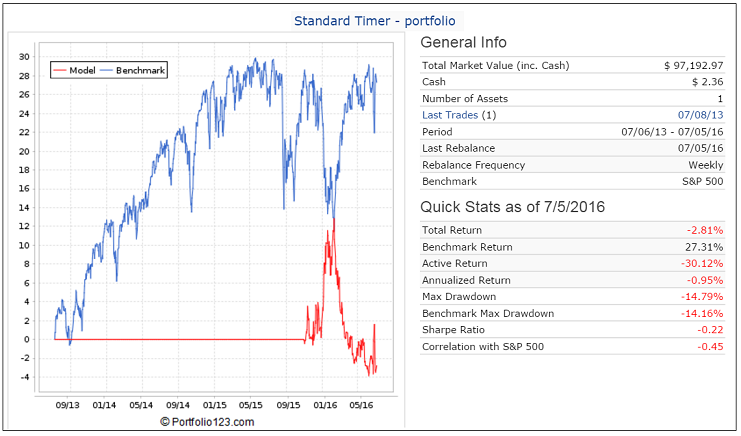
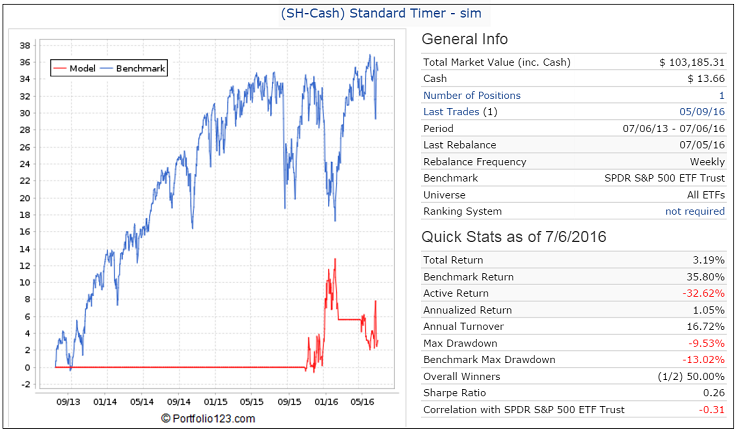
A typical example is my (SH-Cash) Standard Timer.
The portfolio which has been live since 3/18/2016 shows a continuous investment in SH from 11/2/2015 onward.
The simulation done today shows two periods when the model was in SH: 11/2/2015 to 2/22/2016 and from 5/9/2016 onward.
The only explanation for this discrepancy is that the data used for the sell signal must have been revised after 3/18/2016 to provide a sell signal on 2/22/2016 for the most recent simulation. Therefore the point-in-time data which prevailed on 3/18/2016 has now retroactively been changed, and is not point-in-time, which makes the simulation wrong.
While most other things on p123 are great, i have to say that changes to the point-in-time data are very annoying.
Marco & team,
there should be a way that point-in-time data are locked, thereby preventing 3rd party database updates to screw up our backtests and timing models.
Do you really want that? What about new models and simulations? Shouldn’t they use correct PIT data?
PIT data should reflect what an investor would have know at the time the simulated model made a decision. If the DB has a transcription error that is unique to itself, for example, it should be corrected.
Walter,
You build a new model and your simulation tells you that it performs well. Then you make a portfolio from it and let it run for a few months. Eventually the portfolio will diverge from the simulation, because the portfolio uses PIT data, whereas the simulation uses revised PIT data.
So do you think that is perfectly OK ?
What is needed is a list of data that may get revised so we can avoid using those factors in our models.
I have to agree with Georg on this one. Third party updates to the database MAY be PIT but only from the point of view of the third party, not from P123’s perspective. In other words, if data was “known” to the public on Monday morning prior to start of trading, the third party will log the data for that date, regardless of whether or not P123 is capable of processing the data and having it available to subscribers for that date. That is one issue that leads to misleading and actually invalid backtest results. Another issue is trust of whether this third party is actually accounting for all delays in processing the data when back-updating the database. The third issue is loss of confidence when backtest results keep changing. As an engineer, Walter, I am sure you are aware that if you have a port that suddenly stops performing, you need a stable backtest simulation to help diagnose what is going on i.e. some of the possibilities are: different market conditions, P123 s/w bug, change in the computation behind a factor, or breakdown of the port design. If you can’t repeat the results from one day to the next then there is no ability to diagnose or learn from what is going on.
The lack of stable backtest is the prime reason why I took down all of my published backtest results. It would be dishonest to continue to publish such results when the results change on a regular basis. Without a stable backtest we are left with a fancy overpriced screener capability. These points are far more important than getting the “latest” data that is not necessarily historically accurate. We have lived with “imperfect data” up to this point in time. Why do people find it necessary to change it for another version of imperfect data??
If a model fails when the DB is corrected, then it’s a bad model. There’s really no point (no pun intended) in propagating DB errors. Are there examples of gratuitous DB changes?
I need some time to ponder examples you gave. But, you’re right, as an engineer I have plenty of experience with simulations and dealing with simulator and model issues. As a result, I have a healthy skepticism regarding their results and that’s with a world that is largely deterministic.
Thanks,
Walter
EDIT: It seems to me that we need a taxonomy of DB errors. Perhaps something like transcription, delayed PIT, … ?
From an engineering perspective, one wants to nail down anything that moves. That way, if lack of repeatibility starts to occur, you know immediately that there is a problem that needs to be investigated and addressed. Otherwise, we are just guessing and things fall thru the cracks.
This would be good. One area that concerns me is spillover on Monday mornings. There is heavy market activity some weeks and no doubt Compustat (or whomever is processing the data) has difficulty completing the task and extends beyond the weekend. If they are back-filling the database how do they know what was going on 10 years ago? They surely must be using some ideal conditions, or perhaps some canned delays.
I am also struggling with the definition of Point In Time. I had interpreted it as “historically accurate” but I have seen it interpreted as being “not a time series” but a database with data/time logged. I’m not referring to the Compustat data but another website/source. In other words PIT may not be associated with historical accuracy, it really depends on the provider.
One other concern that I have is whether or not Compustat is updating as per revised figures or as originally reported. For backtest purposes, our data can only be as originally reported (+ delays through Compustat and P123). Otherwise, price action is not aligned with fundamental data, a huge problem.
If the profitability of your [whatever] relies on a piece of incorrect PIT data, it’s junk. What is the probability you’ll continue to get a similar error, in your favor, in real-time?
But it does make a difference whether the update of the PIT data is a clerical type error or not. The data error would have to be something that someone AT THE TIME could have recognized as an error, and fixed it. Not something that relies on a hindsight view. True, we may only find the error in hindsight, but that’s different than whether or not they could have been more diligent and fixed the error PIT.
PIT is designed to avoid data snooping and look-ahead bias. But since the DB we use isn’t continuously updated in real-time, the question of data latency is interesting. I think this is one of the issues conveyed earlier. I’m not clear on how latencies are handled … or how they should be handled.
There are other ways that a designer can vet his sim besides having P123 change the data
I almost want to agree with the above statement. However, we have all been investing with this “bad data” for several years now. If the data hasn’t been fixed by now, and traders are still solvent and happily using P123 tools then why would we want the historical data modified? Modifying the data is not risk-free, and the results are not guaranteed to be better by any means. In my opinion, leaving as is has many more benefits than having a third party making ongoing and unknown changes.
I’m with Walther on this subject. I’d rather start from in hindsight “perfect” data to model economic relationships, as opposed to a database full of errors.
I’m not so much concerned about the impact on (highly overfitted?) hedging/timing strategies and sims. Please bear in mind that a backtest should not be regarded as the historical “truth”, but as a “test”. A test seeks to estimate the performance of a model. If a model’s performance displays significant changes based on minor changes of one variable, I’d be really worried about the model.
What P123 should do, however, is to come up with a log of data changes. This way, system developers could be alerted to differences in data affecting the performance of sims.
random errors are not likely to be much of a problem for sims that have lots of trades. Random errors will even out.
Look ahead bias is the worst problem
There can be a problem if other widely read sources or data bases have the information but we at P123–rebalancing our ports in the morning–do not have that information due to data latencies. This gets to be a real problem if the database is later updated to make the sim performance seem like we would have had the data when we rebalanced a port in real time.
I guess I would come down against updating the database to correct for data latencies. For sure we need to correct any look ahead bias.
I do not know where P123 stands on this. I think Marco has worked recently to improve (or completely resolve) some of these issues with earnings estimates revisions. Also some of this may have been resolved with “snaphots.” Obviously, Marco is the expert on this.
I wonder, is some of the timing data used in the port/sim in the original post from the FED? I think Marco has a hard time with this data–they do not claim to even make an effort a PIT at the FED. For example, GDP and employment data is constantly revised. Marco has to work on this data–I think.
Here is what P123 has on their website prior to log-in:
“Are you looking to Create your own strategy? It’s all here: institutional quality point-in-time data and an insanely fast simulation engine.”
So it is supposed to be point-in-time data and not “revised point-in-time” data.
Another sticky issue (after a change to the historical data) is the effect on the R2G portfolios. Are the published equity curves, pre-release or post-release, no longer valid? Do they need to be regenerated? Personally, I review all my private portfolios and those exhibiting a major disturbance are rebuilt and the incubation period restarts. This is time consuming.
I think that all data using estimates should definitely not ever be revised, like SPEPSCY or SPEPSCNY for example. After all these figures are just estimates, and the revised figures are also estimates. Estimates are never accurate, and both, the original and revised estimates are likely to be wrong. So what is the benefit of the revision?
Cyberjoe - first of all, it is not a database “full of errors”. Second, if the database is not historical truth then why do you care if there are a few errors?
A static database is much more important than correcting a few errors for the simple reason that it is the only way for us to detect P123 problems or subtle algorithmic changes. And this is done by simply observing that a sim’s results have changed. It took two years for P123 to realize there was a problem with estimates simply because there is no accounting for changes in sim results.