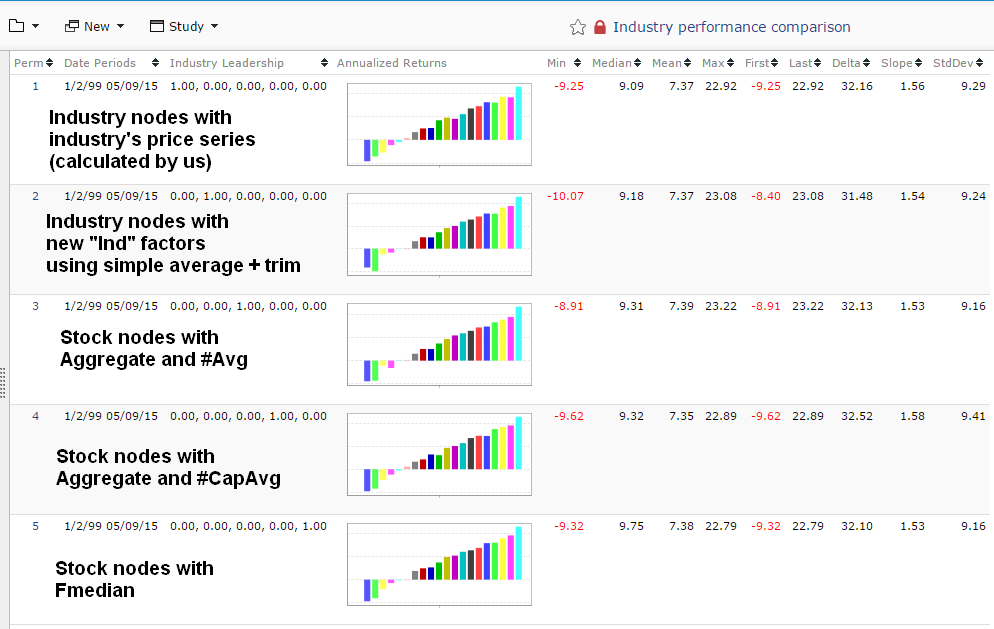
Yes! And that’s exactly why this “controversy” is so perplexing. How could you not be happy the the change to the new Ind protocol, which removes a troublesome source of large random fluctuations and enhances the likelihood of the factor performing for you out of sample in a manner consistent with how it performed in sims? While we can never expect perfection in this regard since the future is necessarily unknown, it would seem that anything that removes randomness from the modeling process is a plus. Couple that with the fact that you can go back to the old way if you want via the Aggregate function . . . What is the problem?
Again, to my mind, whether it’s specifically articulated or not, I think this all comes down to an assumption that the past is sacrosanct and could not and should not change. Although superficially that would appear to be the case, in fact, it is a flawed assumption in this field.
There is no past that is available to us or anyone else in the investment community to work with. What is typically thought of a fixed past is, in fact, a model.
The first set of models is at the company level. No matter how great a set of information systems is used, profit cannot be precisely counted. Some things can be, but many other are determined by modeling assumptions some of which are highly controversial within the accounting field. That;'s why we have two income statement; one being called the cash flow statement, which counts cash in minus cash out and another, called the income statement, which counts cash in for a particular ordinary business source (revenue) minus costs modeled with the aim of matching revenue to expenses (a brutally difficult task considering that many expenses support revenue over periods that do not match the period in which the spending occurs). And right now, the hot topic at FASB is valuation-based profit, which means that ordinary operating expenses should include an amount to reflect (model based) estimates of the change in the total “market value” of the company’s assets. I think this change would be a nightmare and if it comes to pass, I’ll probably have to work up a metric for us that adjusts net incomer, eps, etc, to eliminate it. Either way, this Ind change is chickens** compared to the potential impact of this sort of thing.
Next are models of the economy. There’s no exact science to counting GDP, or any one of countless other indicaotrs. Don’t you notice the significance of revisions? Do you know what the final number is? It’s the number we have after the government decides that enough si enough and to simply stop looking to revise. But that doesn’t mean it’s firm.
Now, let’s move on t databases. Go back to the white paper I posted when we switched to Compustat. There is no single correct way to take the already-model-based data in the 10-Ks and 10-Qa and convert them into the kinds of numbers we can work with. In that paper, I explained and illustrated substantial differences between what Reuters and Compustat do. And Zachs is still different. And there are other data vendors that arer also different.
Ultimately, a quest for data stability is a quest for the outlawing of change for the better, something I do not think we can or should support and I doubt the majority of our users would support that. Steve, I’m especially perplexed why you, one who has often spoken out so effectively against excessive attention to simulated results (as opposed to live results) cares so much about this topic. Your old sims are what they are. As Denny said in a post, the new items make for the new normal.
All this would be rightfully upsetting if it meant that all your models were anchored to nothing and could fluctuate wildly based on changes/improvements that come down the pike in the future. Whether that fear is valid or not depends on your models. If your models are anchored in legitimate ideas about relating to factors that genuinely influence stocks prices, changes should be modest. (Through all the changes made here, including the change to Compustat, none of my models (not just the new I use live but the ridiculous large number stored in my account that I created for one work-related reason or another) have changed in a meaningful way. Some improved. Some deteriorated. But all of the changes were minor. None were such as to cause me to suddenly reject a once-thought-to-be-good model or accept a once-thought-to-ber-bad model. If a model changes significantly in response to the sorts f changes we’ve been introducing, whether Composts, Ind, error corrections, data vendor cleanups, etc., that’s a sign that the model is overly subject to the dreaded “R” word, randomness, and needs to be reviewed.
I’ve long argued that the sort of statistical robustness testing done by so many is nonsense because all it does is perfect a prediction of the past. Frankly, this Ind change is probably the best robustness test you got since the last data change. Maybe i should come up with a list of other changes users could introduce on a do-it-yoursdelf factor-definition-basis (i.e. use Aggregate to introduce more changes into Ind comparison; recreate some of the old Reuters factor, etc.) to run a set of REAL robustness checks.